
Hi there, this is Ye-Xin Lu (鲁叶欣).
I graduated from School of the Gifted Young, University of Science and Technology of China (USTC) with a bachelor’s degree in electronic information engineering.
I am currently a second-year Eng.D student at the National Engineering Research Center for Speech and Language Information Processing (NERC-SLIP) of USTC, supervised by Prof. Zhen-Hua Ling (凌震华).
My CV can be downloaded here.
My main research interests lie in text-to-speech synthesis, speech enhancement, and speech coding.
🔥 News
- 2025.05: I have been awarded a scholarship by the China Scholarship Council (CSC) to visit the National Institute of Informatics for six months, under the supervision of Prof. Junichi Yamagishi.
- 2025.05: One conference paper is accepted by Interspeech 2025.
- 2025.04: One journal paper is accepted by Neural Networks.
📝 Publications
🎙 Speech Enhancement
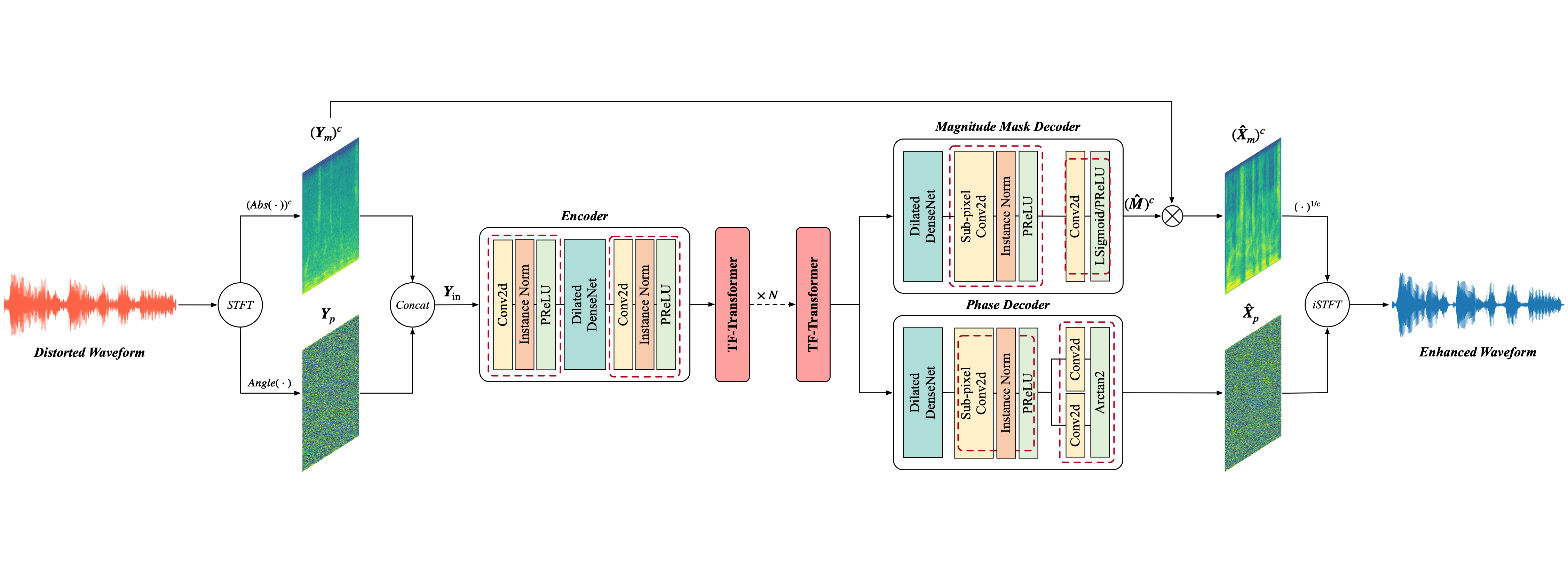
MP-SENet: A Speech Enhancement Model with Parallel Denoising of Magnitude and Phase Spectra (Conference Version)
Explicit Estimation of Magnitude and Phase Spectra in Parallel for High-Quality Speech Enhancement(Journal Version)
Ye-Xin Lu, Yang Ai, Zhen-Hua Ling

- In this paper, we propose a novel Speech Enhancement Network that explicitly enhances Magnitude and Phase spectra in parallel, dubbed MP-SENet.
- MP-SENet is the first speech enhancement model that realizes explicit phase estimation and optimization by using phase parallel estimation architecture and anti-wrapping losses.
- MP-SENet mitigates the compensation effect between the magnitude and phase by explicit phase estimation, elevating the quality of enhanced speech to a new level.
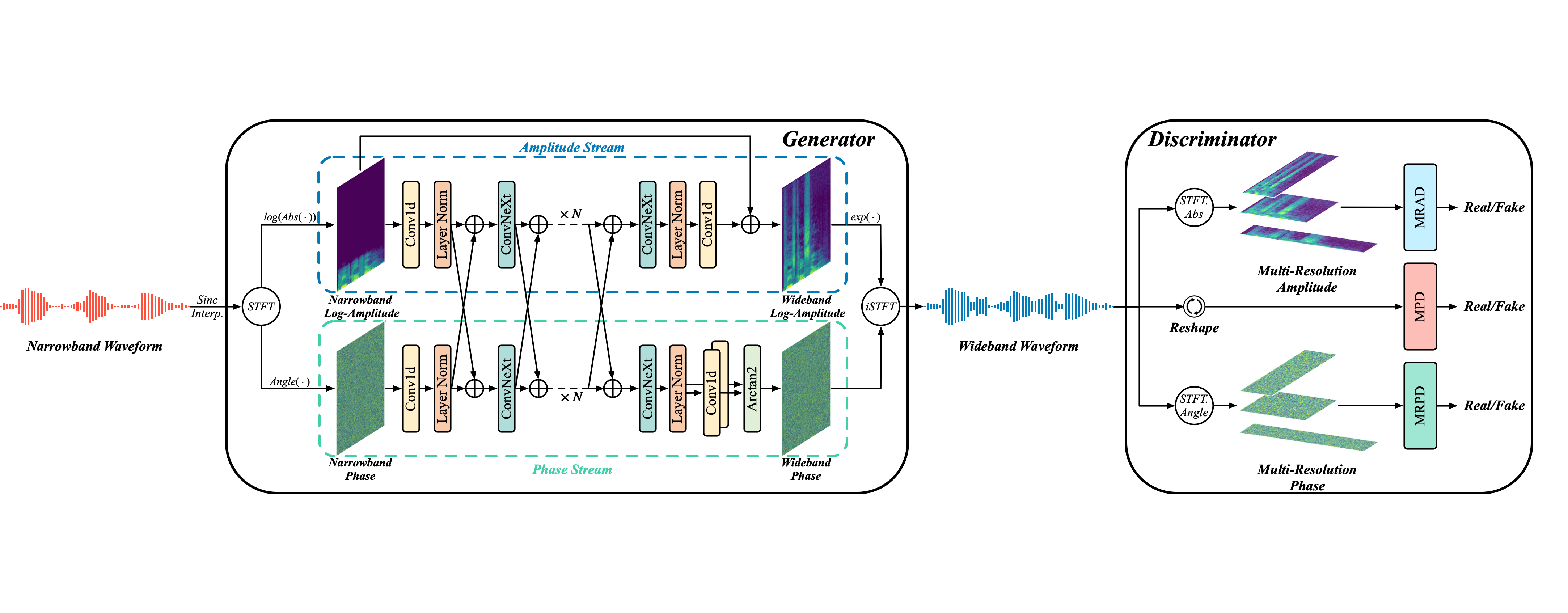
Ye-Xin Lu, Yang Ai, Hui-Peng Du, Zhen-Hua Ling

- In this paper, we propose a generative adversarial network-based speech bandwidth extension (BWE) model with the parallel prediction of Amplitude and Phase spectra, dubbed AP-BWE.
- AP-BWE realizes high-quality speech BWE by explicit amplitude-phase estimation and multi-resolution amplitude-phase discrimination.
- AP-BWE realizes efficient speech BWE by using all-convolutional architecture and all-frame-level operations.
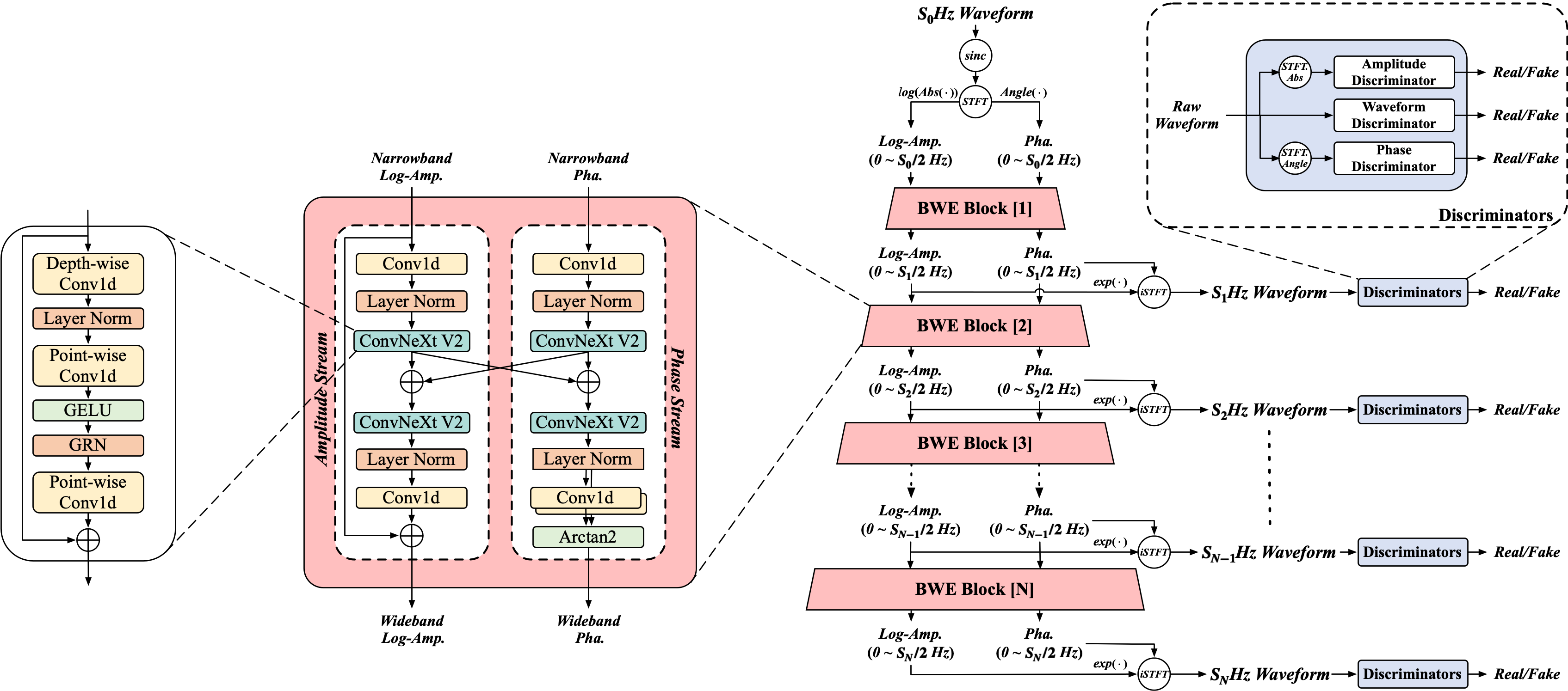
Multi-Stage Speech Bandwidth Extension with Flexible Sampling Rates Control
Ye-Xin Lu, Yang Ai, Zheng-Yan Sheng, Zhen-Hua Ling
- In this paper, we propose a multi-stage speech BWE model named MS-BWE, which can handle a set of source and target sampling rate pairs and achieve flexible extensions of frequency bandwidth.
- MS-BWE comprises a cascade of BWE blocks, with each block featuring a dual-stream architecture to realize amplitude and phase extension, progressively painting the speech frequency bands stage by stage.
- We adopt the teacher-forcing strategy to mitigate the discrepancy between training and inference.
🗣️ Speech Synthesis
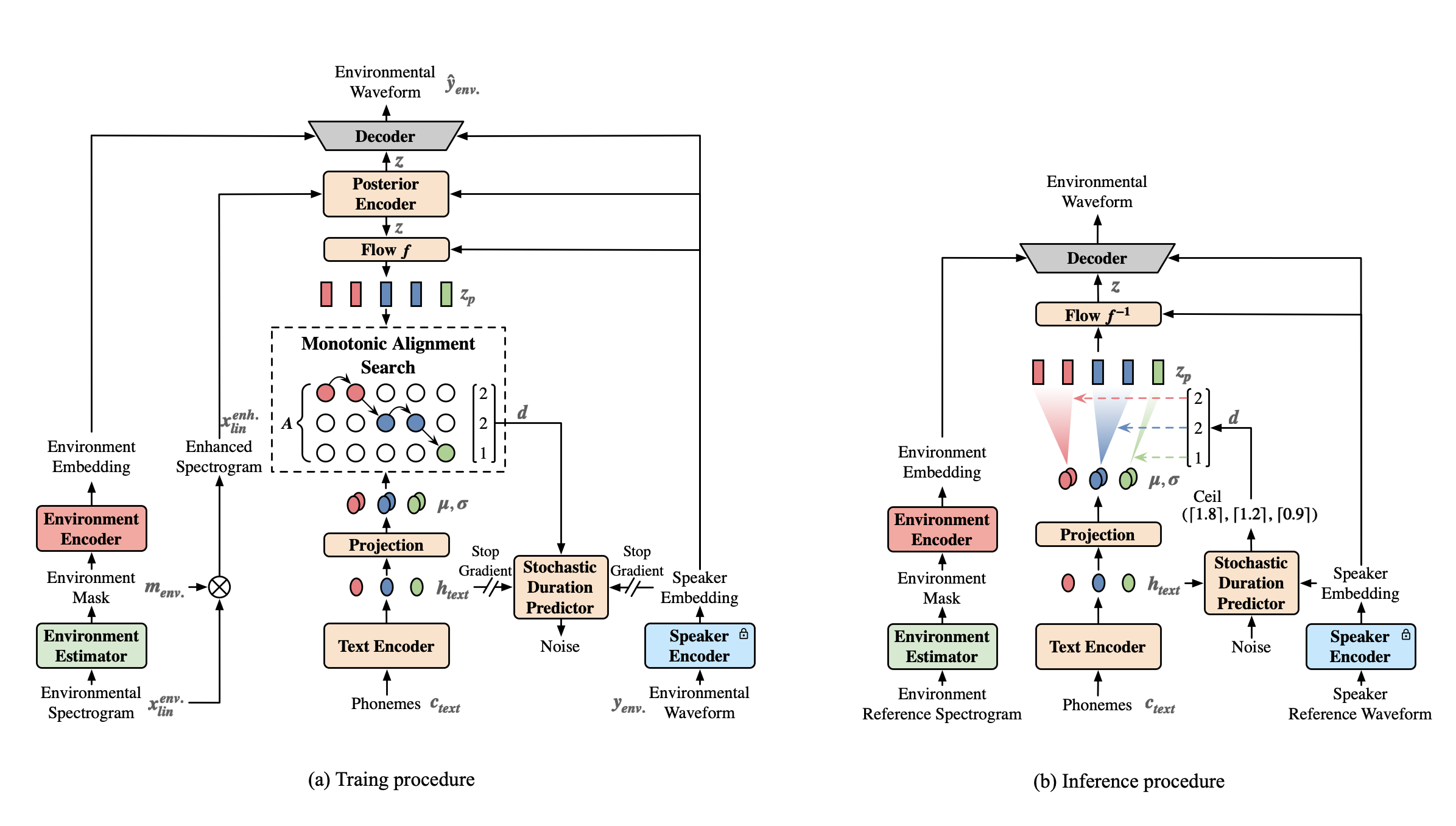
Incremental Disentanglement for Environment-Aware Zero-Shot Text-to-Speech Synthesis
Ye-Xin Lu, Hui-Peng Du, Zheng-Yan Sheng, Yang Ai, Zhen-Hua Ling

- In this paper, we propose an Incremental Disentanglement-based Environment-Aware zero-shot text-to-speech (TTS) method, dubbed IDEA-TTS, that can synthesize speech for unseen speakers while preserving the acoustic characteristics of a given environment reference speech.
- IDEA-TTS is capable of environment-robust TTS, environment-aware TTS, and environment conversion with a single model.
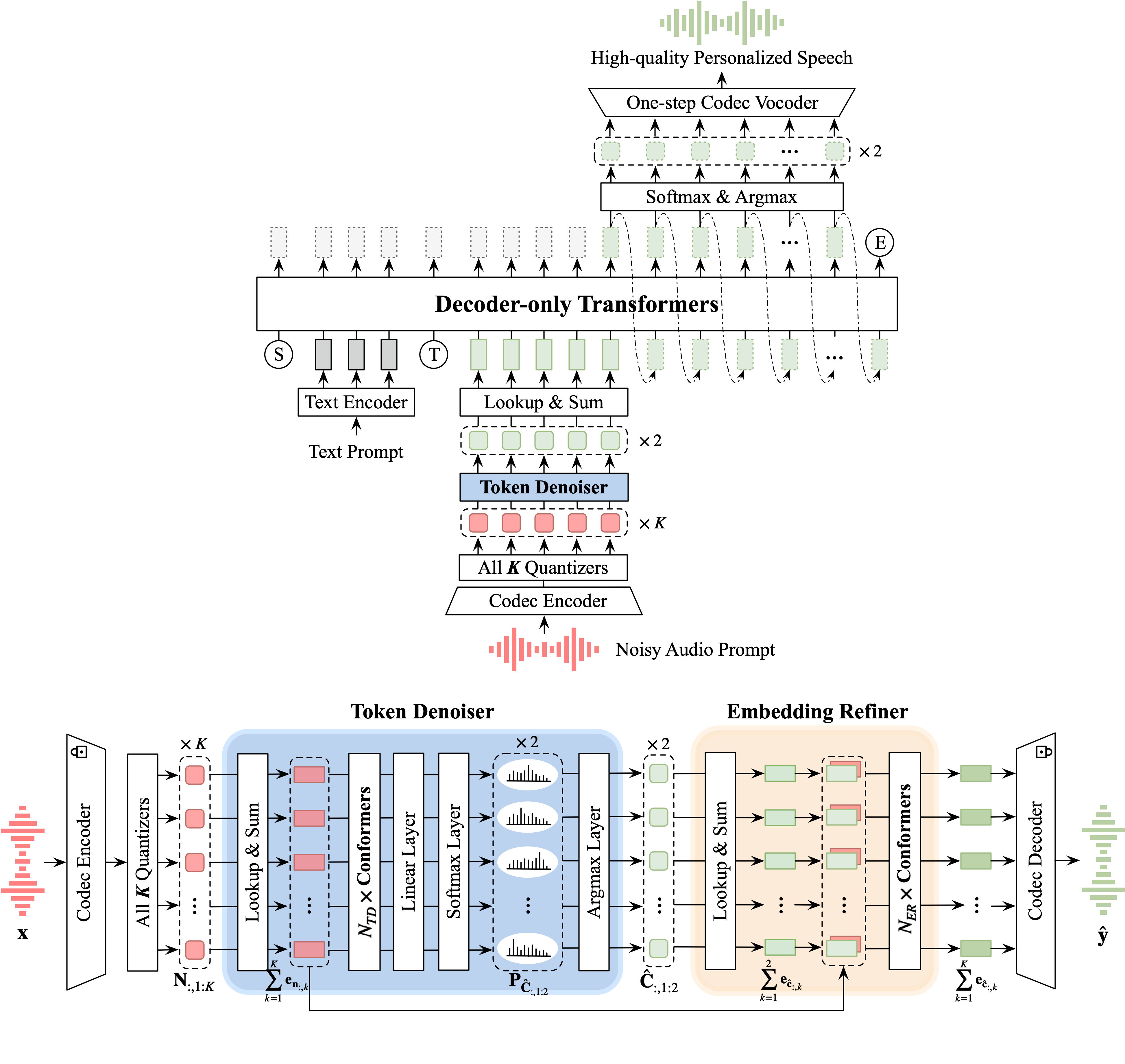
Improving Noise Robustness of LLM-based Zero-shot TTS via Discrete Acoustic Token Denoising
Ye-Xin Lu, Hui-Peng Du, Fei Liu, Yang Ai, Zhen-Hua Ling
- In this paper, we propose a novel neural codec-based speech denoiser and integrate it with the advanced LLM-based TTS model, LauraTTS, to achieve noise-robust zero-shot TTS.
- The proposed codec denoiser outperforms state-of-the-art speech enhancement (SE) methods in DNSMOS-based metrics.
- The proposed noise-robust LauraTTS (NR-LauraTTS) surpasses the approach using enhanced audio prompts with minimal impact on the model’s computational complexity.
📚 Other Publications
Journal
-
IEEE/ACM TASLP 2024 APCodec: A Neural Audio Codec with Parallel Amplitude and Phase Spectrum Encoding and Decoding, Yang Ai, Xiao-Hang Jiang, Ye-Xin Lu, Hui-Peng Du, Zhen-Hua Ling.
-
IEEE SPL 2023 Long-frame-shift Neural Speech Phase Prediction with Spectral Continuity Enhancement and Interpolation Error Compensation, Yang Ai, Ye-Xin Lu, Zhen-Hua Ling.
Conference
-
INERSPEECH 2024 A Low-Bitrate Neural Audio Codec Framework with Bandwidth Reduction and Recovery for High-Sampling-Rate Waveforms, Yang Ai, Ye-Xin Lu, Xiao-Hang Jiang, Zheng-Yan Sheng, Rui-Chen Zheng, Zhen-Hua Ling.
-
INERSPEECH 2024 BiVocoder: A Bidirectional Neural Vocoder Integrating Feature Extraction and Waveform Generation, Hui-Peng Du, Ye-Xin Lu, Yang Ai, Zhen-Hua Ling.
-
NCMMSC 2023 APNet2: High-Quality and High-Efficiency Neural Vocoder with Direct Prediction of Amplitude and Phase Spectra, Hui-Peng Du, Ye-Xin Lu, Yang Ai, Zhen-Hua Ling.
-
NCMMSC 2022 Source-Filter-Based Generative Adversarial Neural Vocoder for High Fidelity Speech Synthesis, Ye-Xin Lu, Yang Ai, Zhen-Hua Ling.
-
SLT 2024 Pitch-and-Spectrum-Aware Singing Quality Assessment with Bias Correction and Model Fusion, Yu-Fei Shi, Yang Ai, Ye-Xin Lu,, Hui-Peng Du, Zhen-Hua Ling.
-
SLT 2024 MDCTCodec: A Lightweight MDCT-based Neural Audio Codec towards High Sampling Rate and Low Bitrate Scenarios, Xiao-Hang Jiang, Yang Ai, Rui-Chen Zheng, Hui-Peng Du, Ye-Xin Lu, Zhen-Hua Ling.
-
SLT 2024 Stage-Wise and Prior-Aware Neural Speech Phase Prediction, Fei Liu, Yang Ai, Hui-Peng Du, Ye-Xin Lu, Rui-Chen Zheng, Zhen-Hua Ling.
🎓 Educations
- 2021.09 - 2026.06 (Expected), Eng.D, School of Infomation Science and Technology, University of Science and Technology of China, Hefei.
- 2017.08 - 2021.06, Undergraduate, School of the Gifted Young, University of Science and Technology of China, Hefei.
- 2014.09 - 2017.06, Anhui Nanling High School, Wuhu.
💻 Internships
- 2025.10 - 2026.04, NII, Yamagishi Lab, Tokyo.
- 2025.04 - 2025.09, Tencent, AI Lab, Beijing.
- 2022.07 - 2023.10, iFLYTEK, Hefei.